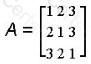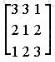A computer vision model is trained to identify cats on a training set that is composed of both cat and dog images. The model predicts a picture of a cat is a dog. Which of the following describes this error?
A data scientist is building a model to predict customer credit scores based on information collected from reporting agencies. The model needs to automatically adjust its parameters to adapt to recent changes in the information collected. Which of the following is the best model to use?
A data scientist needs to analyze a company's chemical businesses and is using the master database of the conglomerate company. Nothing in the data differentiates the data observations for the different businesses. Which of the following is the most efficient way to identify the chemical businesses' observations?
A data analyst wants to generate the most data using tables from a database. Which of the following is the best way to accomplish this objective?
A movie production company would like to find the actors appearing in its top movies using data from the tables below. The resulting data must show all movies in Table 1, enriched with actors listed in Table 2.
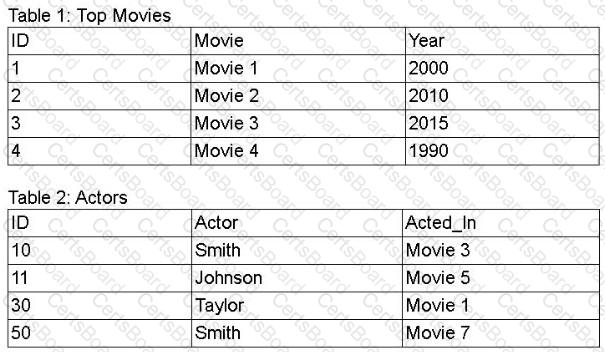
Which of the following query operations achieves the desired data set?
Which of the following problem-solving approaches is a set of guidelines to handle highly variable and not fully apparent situations?
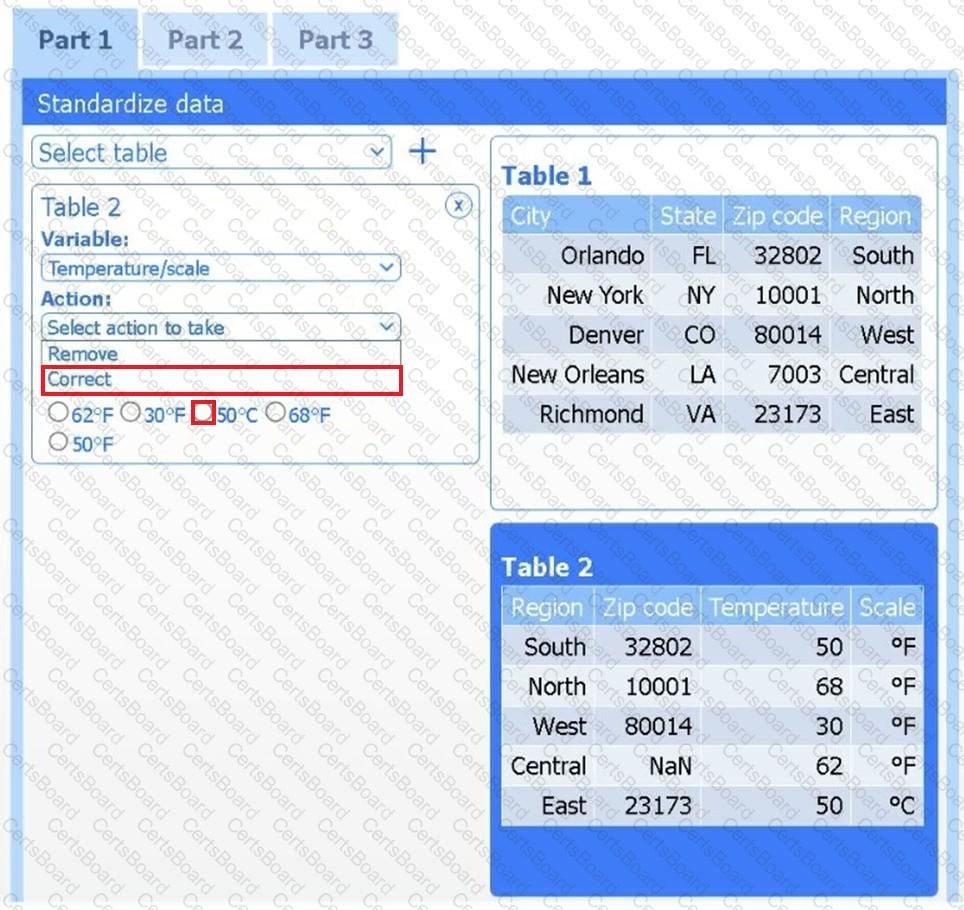
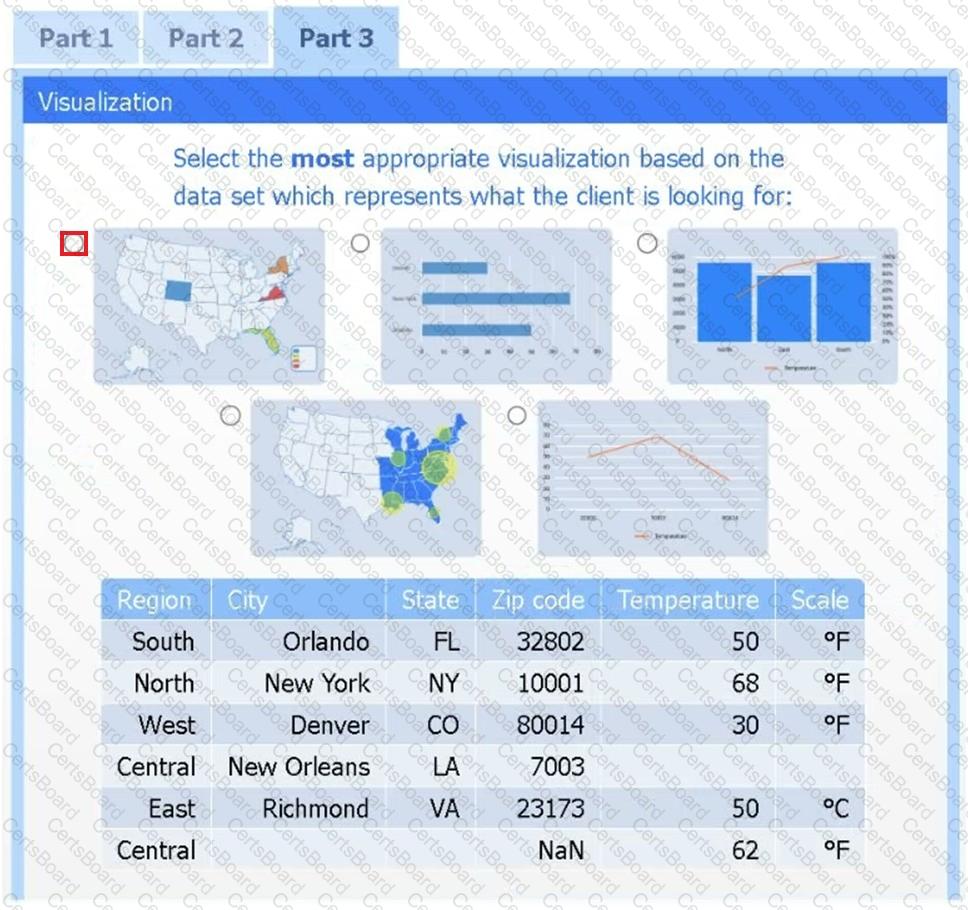
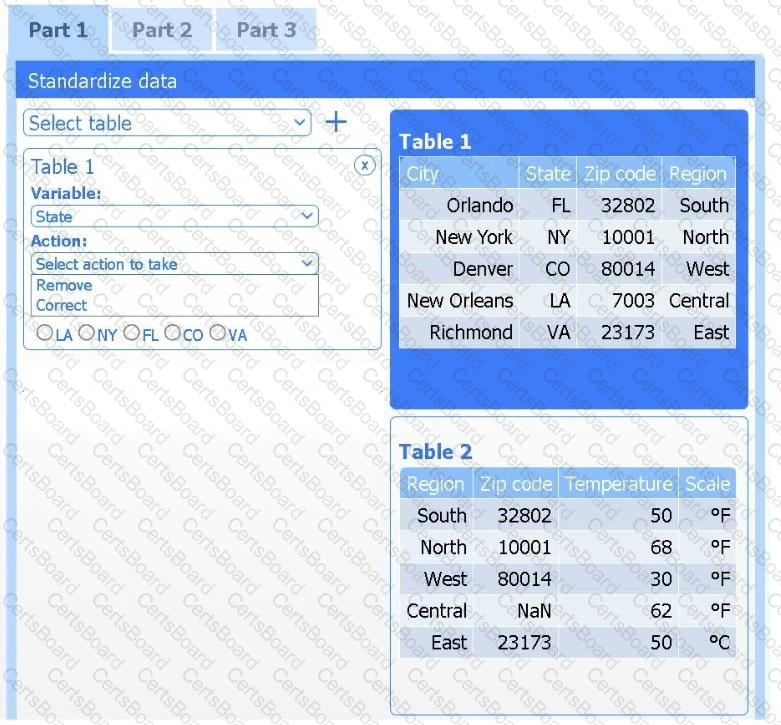
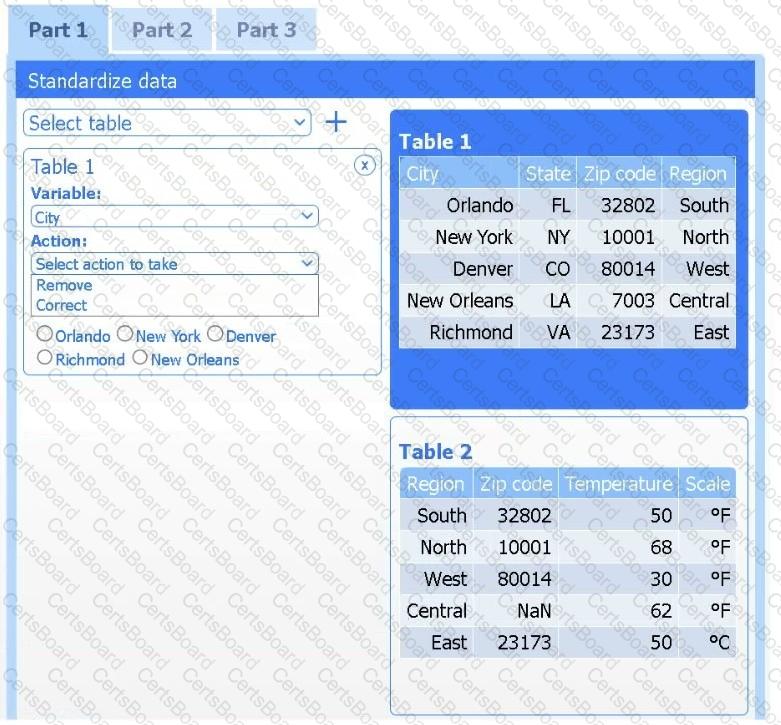
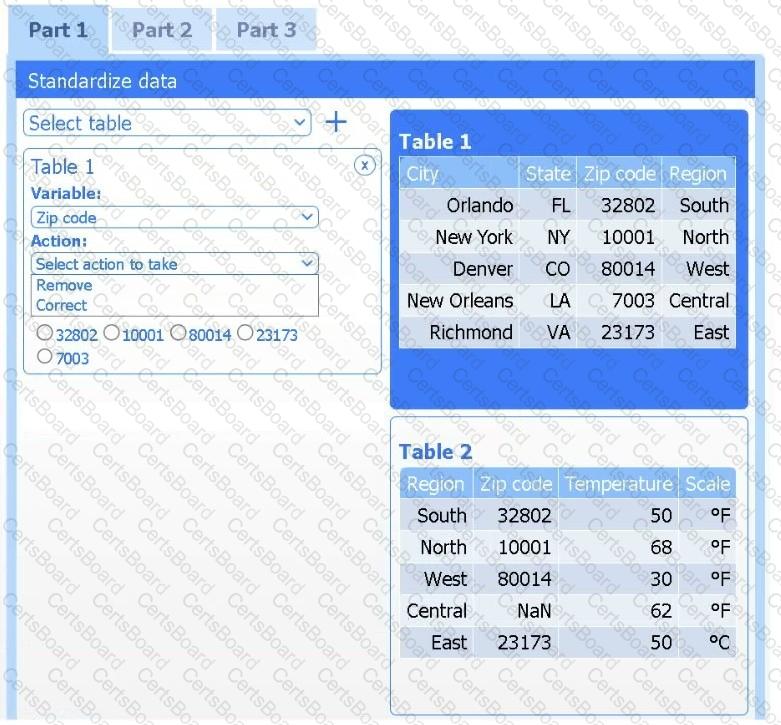
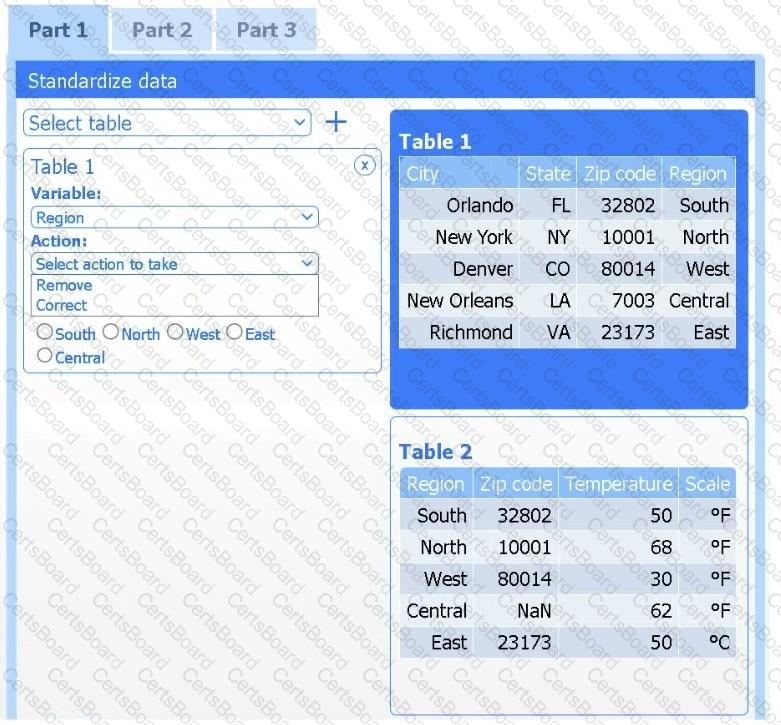
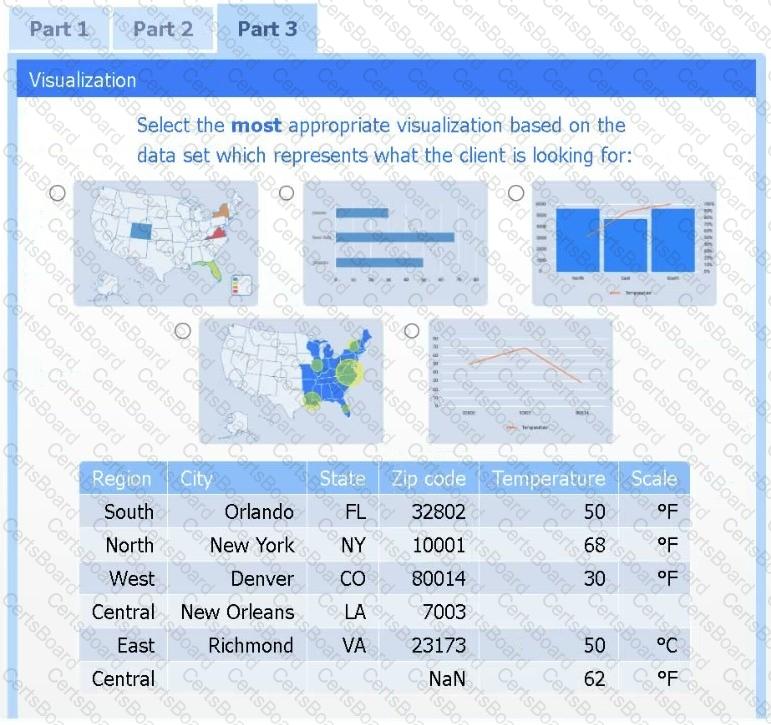
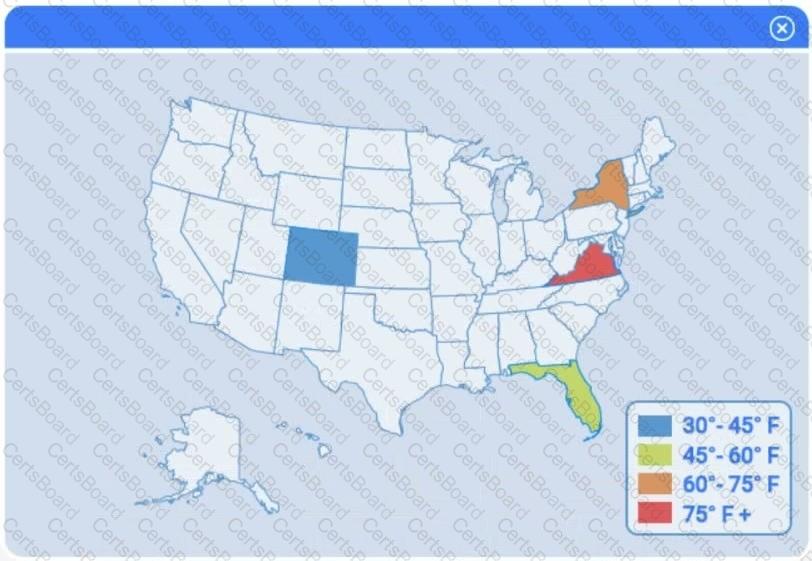
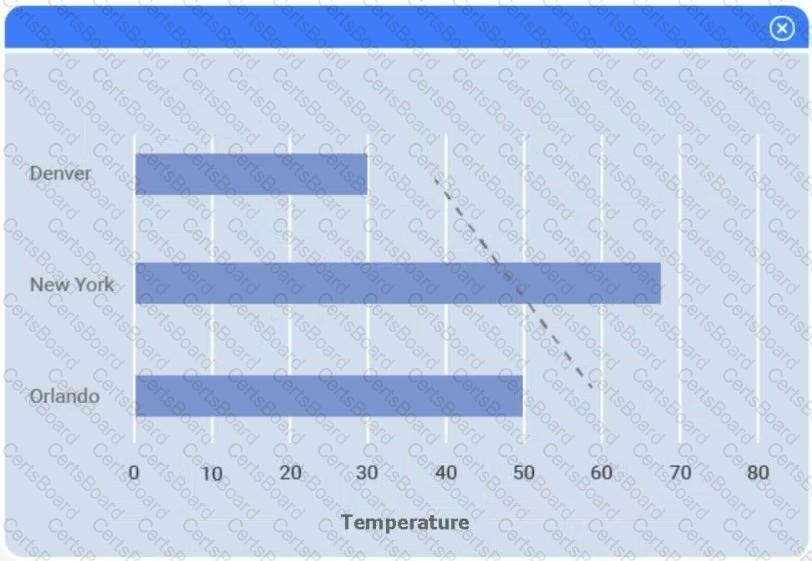
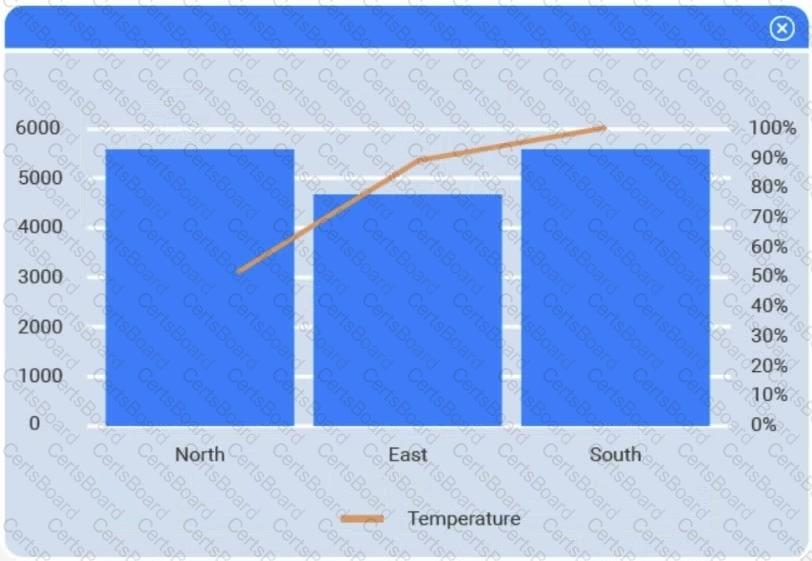
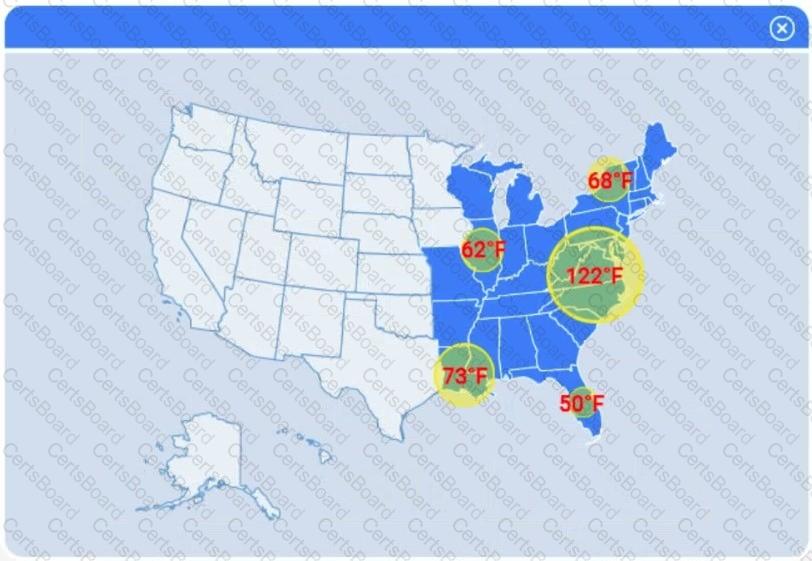
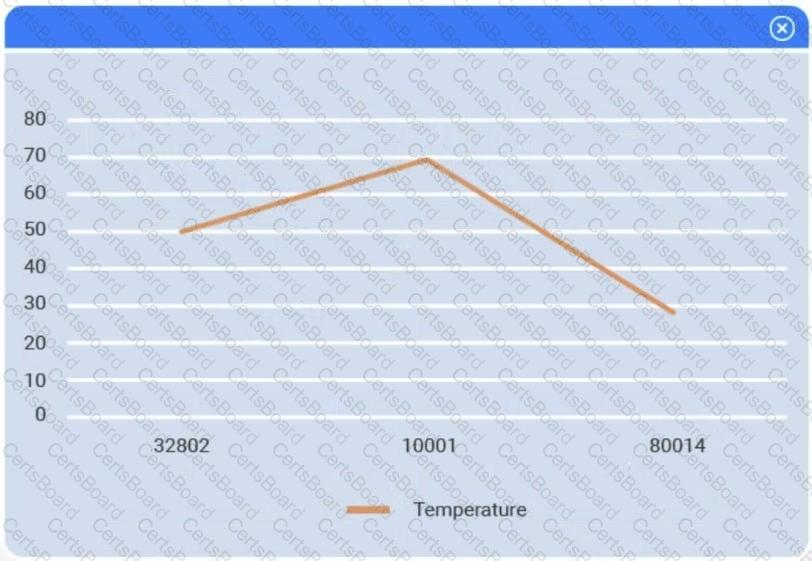
A client has gathered weather data on which regions have high temperatures. The client would like a visualization to gain a better understanding of the data.
INSTRUCTIONS
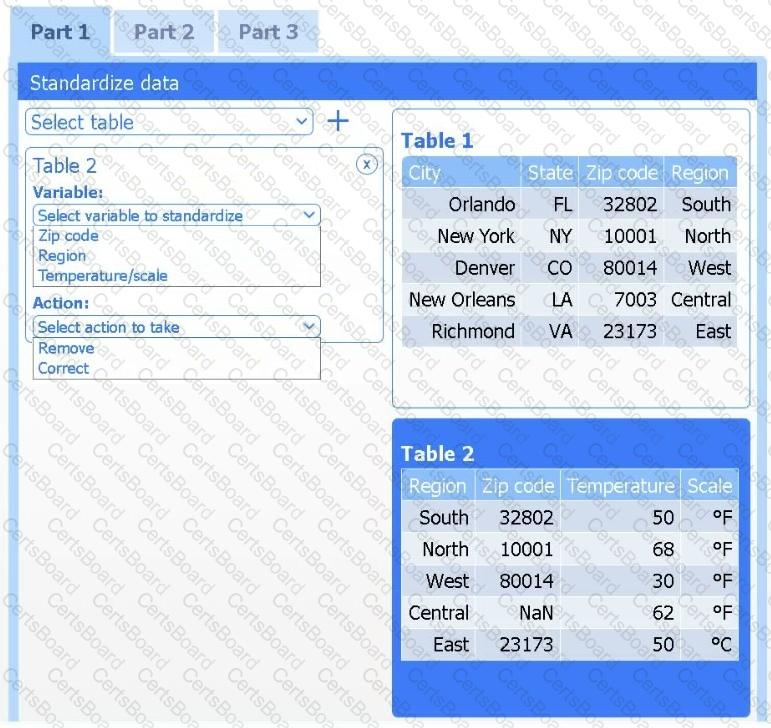
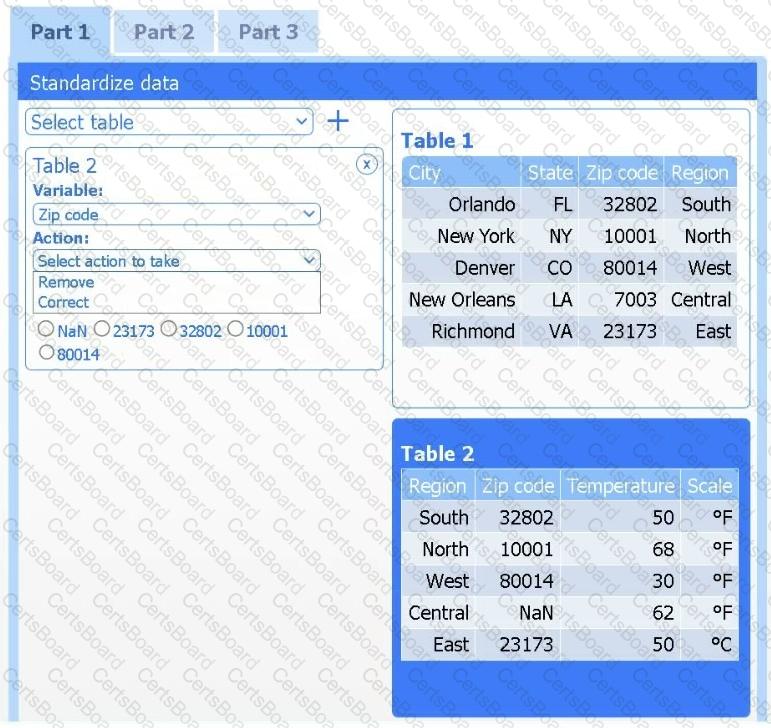
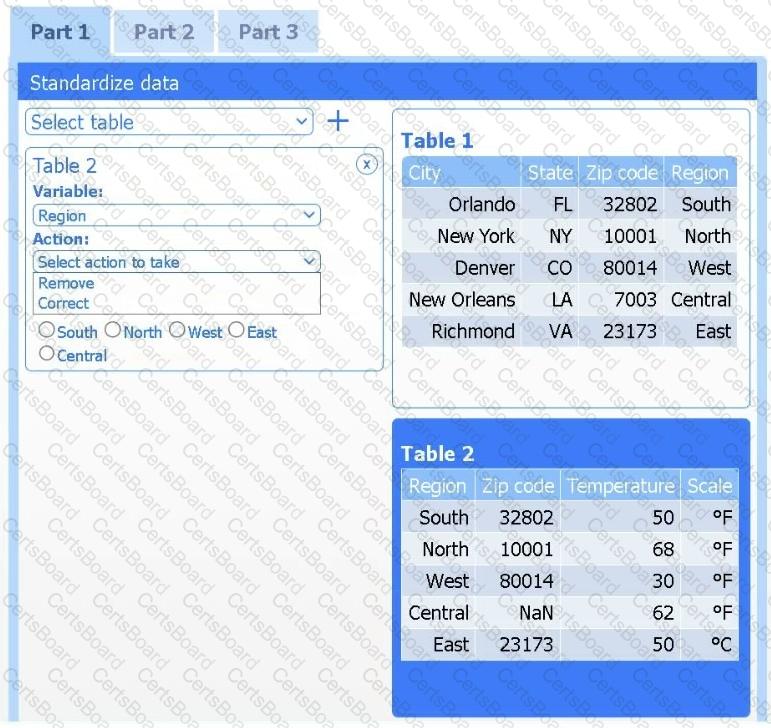
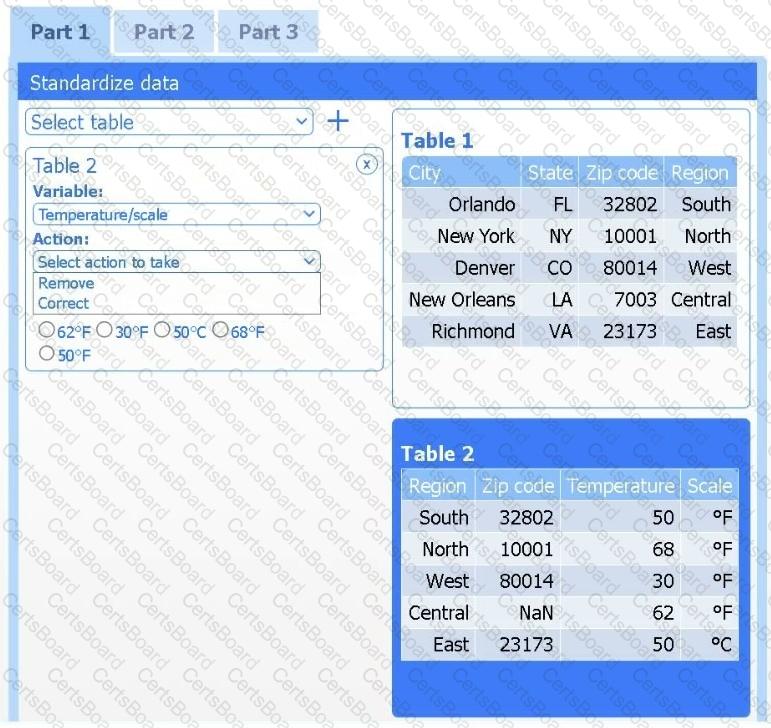
Part 1
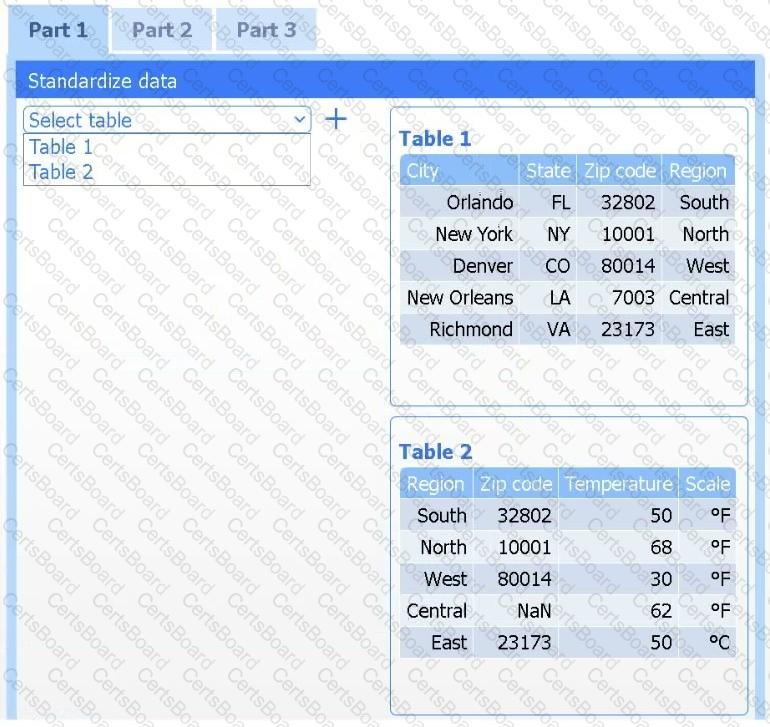
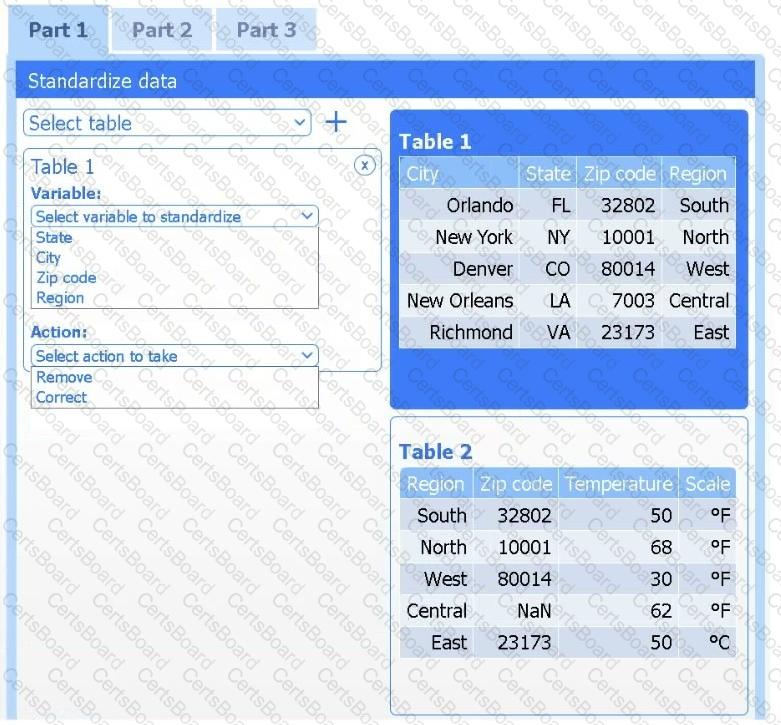
Review the charts provided and use the drop-down menu to select the most appropriate way to standardize the data.
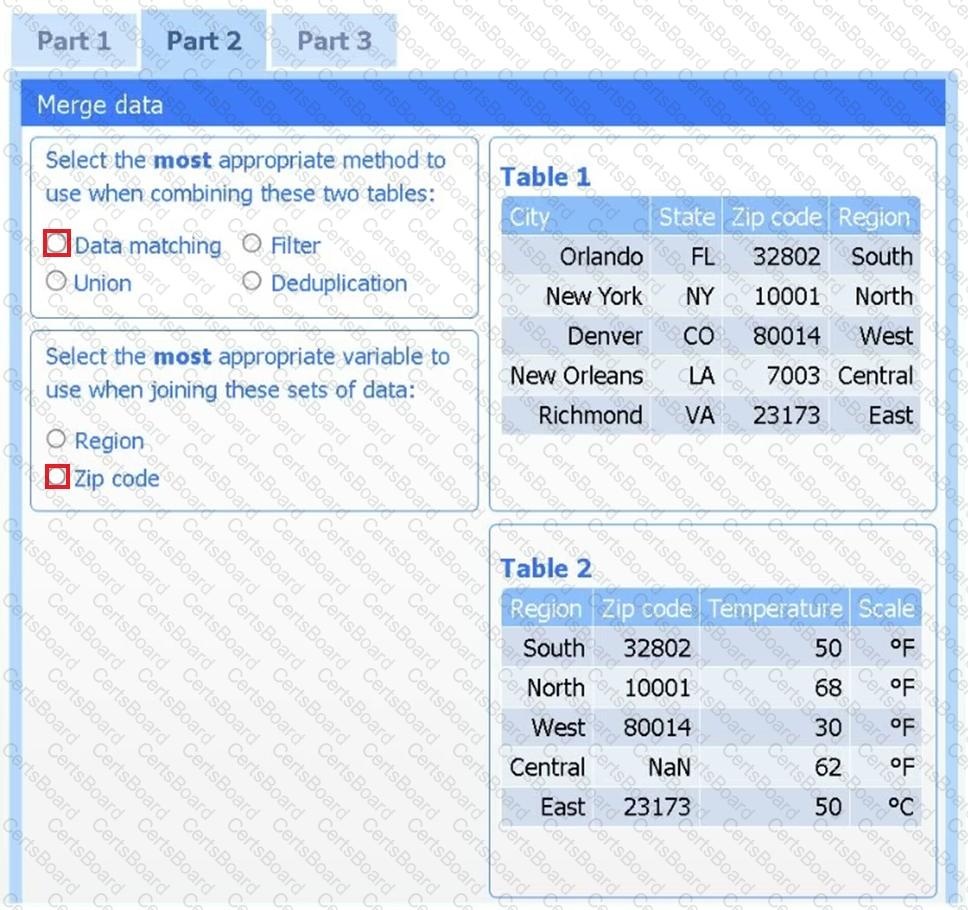
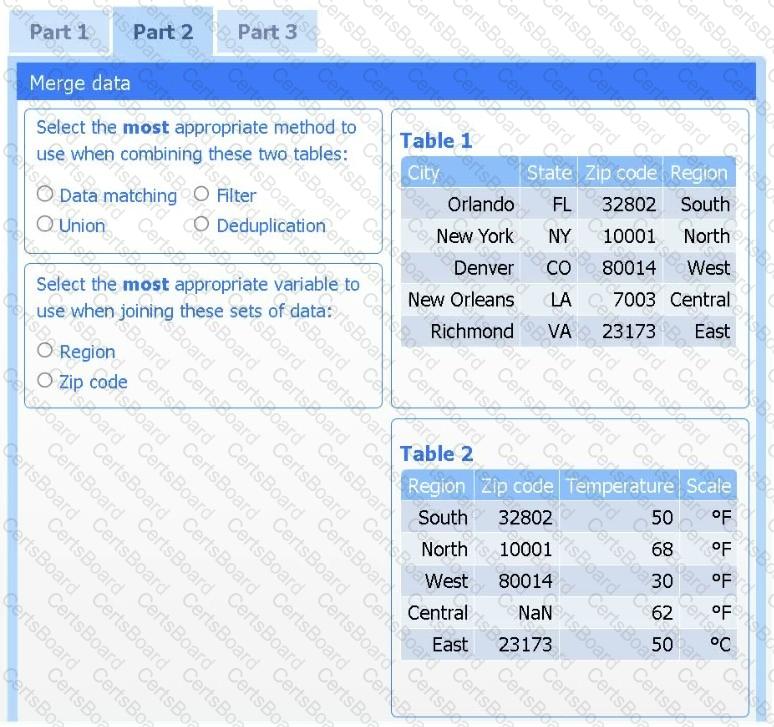
Part 2
Answer the questions to determine how to create one data set.
Part 3
Select the most appropriate visualization based on the data set that represents what the client is looking for.
If at any time you would like to bring back the initial state of the simulation, please click the Reset All button.
A data scientist uses a large data set to build multiple linear regression models to predict the likely market value of a real estate property. The selected new model has an RMSE of 995 on the holdout set and an adjusted R² of 0.75. The benchmark model has an RMSE of 1,000 on the holdout set. Which of the following is the best business statement regarding the new model?
Which of the following environmental changes is most likely to resolve a memory constraint error when running a complex model using distributed computing?

TESTED 31 Jul 2026