You are selling up a new cloud environment. The customer already has a system of record for Its employees and doesn't want to re-create them in Appian. so you are going to Implement LDAP authentication.
What are the next steps to configure LDAP authentication?
To answer, move the appropriate steps from the Option list to the Answer List area, and arrange them in the correct order. You may or may not use all the steps.

You need to generate a PDF document with specific formatting. Which approach would you recommend?
You are developing a case management application to manage support cases for a large set of sites. One of the tabs in this application s site Is a record grid of cases, along with Information about the site corresponding to that case. Users must be able to filter cases by priority level and status.
You decide to create a view as the source of your entity-backed record, which joins the separate case/site tables (as depicted in the following Image).

Which three column should be indexed?
What are two advantages of having High Availability (HA) for Appian Cloud applications?
You are the project lead for an Appian project with a supportive product owner and complex business requirements involving a customer management system. Each week, you notice the product owner becoming more irritated and not devoting as much time to the project, resulting in tickets becoming delayed due to a lack of involvement. Which two types of meetings should you schedule to address this issue?
You are on a protect with an application that has been deployed to Production and is live with users. The client wishes to increase the number of active users.
You need to conduct load testing to ensure Production can handle the increased usage
Review the specs for four environments in the following image.

Which environment should you use for load testing7
Your client's customer management application is finally released to Production. After a few weeks of small enhancements and patches, the client is ready to build their next application. The new application will leverage customer information from the first application to allow the client to launch targeted campaigns for select customers in order to increase sales. As part of the first application, your team had built a section to display key customer information such as their name, address, phone number, how long they have been a customer, etc. A similar section will be needed on the campaign record you are building. One of your developers shows you the new object they are working on for the new application and asks you to review it as they are running into a few issues. What feedback should you give?
As part of an upcoming release of an application, a new nullable field is added to a table that contains customer data. The new field is used by a report in the upcoming release and is calculated using data from another table.
Which two actions should you consider when creating the script to add the new field?
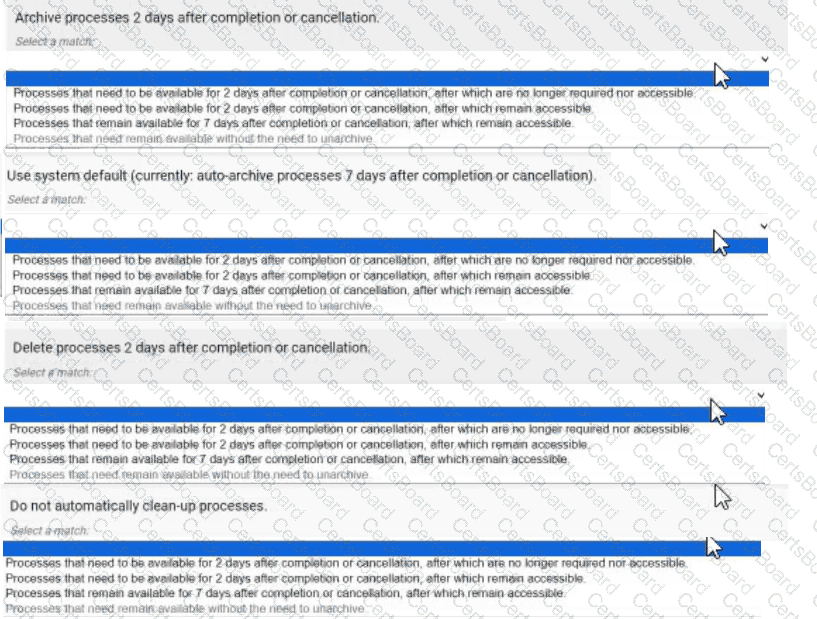
You are deciding the appropriate process model data management strategy.
For each requirement. match the appropriate strategies to implement. Each strategy will be used once.
Note: To change your responses, you may deselect your response by clicking the blank space at the top of the selection list.
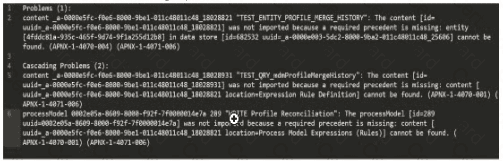
You are taking your package from the source environment and importing it into the target environment.
Review the errors encountered during inspection:
What is the first action you should take to Investigate the issue?

TESTED 02 Aug 2026




