You use an Azure Machine Learning workspace. Azure Data Factor/ pipeline, and a dataset monitor that runs en a schedule to detect data drift.
You need to Implement an automated workflow to trigger when the dataset monitor detects data drift and launch the Azure Data Factory pipeline to update the dataset. The solution must minimize the effort to configure the workflow.
How should you configure the workflow? To answer select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

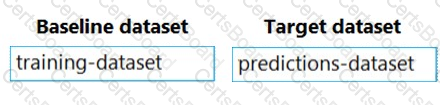
You previously deployed a model that was trained using a tabular dataset named training-dataset, which is based on a folder of CSV files.
Over time, you have collected the features and predicted labels generated by the model in a folder containing a CSV file for each month. You have created two tabular datasets based on the folder containing the inference data: one named predictions-dataset with a schema that matches the training data exactly, including the predicted label; and another named features-dataset with a schema containing all of the feature columns and a timestamp column based on the filename, which includes the day, month, and year.
You need to create a data drift monitor to identify any changing trends in the feature data since the model was trained. To accomplish this, you must define the required datasets for the data drift monitor.
Which datasets should you use to configure the data drift monitor? To answer, drag the appropriate datasets to the correct data drift monitor options. Each source may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.

You tram and register a model by using the Azure Machine Learning Python SDK v2 in a local workstation. Python 3.7 and Visual Studio Code are instated on the workstation.
When you try to deploy the model into production to a Kubernetes online endpoint you experience an error in the scoring script that causes deployment to fail.
You need to debug the service on the local workstation before deploying the service to production.
Which three actions should you perform m sequence? To answer, move the appropriate actions from the list of actions from the answer area and arrange them in the correct order.

You run an automated machine learning experiment in an Azure Machine Learning workspace. Information about the run is listed in the table below:

You need to write a script that uses the Azure Machine Learning SDK to retrieve the best iteration of the experiment run. Which Python code segment should you use?
A)

B)

C)

D)





TESTED 02 May 2024


 Text
Description automatically generated with medium confidence
Text
Description automatically generated with medium confidence